Principal Component Analysis
Tóm tắt
Mở đầu bài viết, ta đưa ra một cái nhìn tổng quan về thuật toán Principal Components Analysis (PCA) và việc giảm chiều dữ liệu. Tiếp đến, ta xây dựng PCA từ ý tưởng đến hoàn thiện bằng toán học. Cuối cùng, ta tìm hiểu về những ứng dụng của PCA và cách sử dụng thuật toán trong python.
Tổng quan
Principal Components Analysis (PCA) là thuật toán học không giám sát với mục đích giảm chiều dữ liệu bằng cách tìm không gian con có số chiều nhỏ hơn không gian ban đầu của dữ liệu.
Giảm chiều dữ liệu
Ta sẽ tìm hiểu về khái niệm giảm chiều dữ liệu qua ví dụ. Ta có tập dữ liệu \(\{x^{(1)}, x^{(2)},.., x^{(n)}\}\), mỗi điểm dữ liệu \(x^{(i)} \in \mathbb{R}^{d}\) thể hiện cho một khách hàng. Một khách hàng \(i\) có những thuộc tính: tuổi, nghề nghiệp, thu nhập, tổng giá trị sản phẩm đã mua,… tương ứng với \(x_1^{(i)}, x_2^{(i)},..., x_d^{(i)}\). Trong các thuộc tính trên có những thuộc tính có thể phụ thuộc lẫn nhau. Ta có thể dùng suy luận để nhận xét rằng, một người có thu nhập cao sẽ chi ra nhiều tiên để mua sản phẩm của công ty, nói cách khác mối quan hệ của thuộc tính “thu nhập” và “tổng giá trị sản phẩm đã mua” có thể biểu diễn bằng hàm số \(y = ax + b\). Do đó, ta chỉ cần một vector \(d - 1\) chiều để biểu diễn \(x^{(i)} \in \mathbb{R}^{d}\).
Những thuật toán giảm chiều dữ liệu sẽ giúp thực hiện việc suy luận mối quan hệ của các thuộc tính một cách tự động và tối ưu nhất từ đó có thể giảm chiều dữ liệu cho tập dữ liệu ban đầu.
Chuẩn hóa dữ liệu
PCA rất nhạy với đơn vị của thuộc tính, sử dụng đơn vị khác nhau của thuộc tính có thể dẫn đến kết quả khác nhau, ví dụ: sử dụng đơn vị cho thuộc tính “thu nhập” là (triệu) sẽ dẫn đến kết quả khác với sử dụng đơn vị là (ngàn). Do đó việc chuẩn hóa dữ liệu là cần thiết cho PCA.
Có nhiều thuật toán chuẩn hóa dữ liệu khác nhau như: Standard Scaling, Min Max Scaling, Robust Scaling, Normailizing,… Việc lựa chọn thuật toán nào sẽ tùy vào mục đích của người dùng.
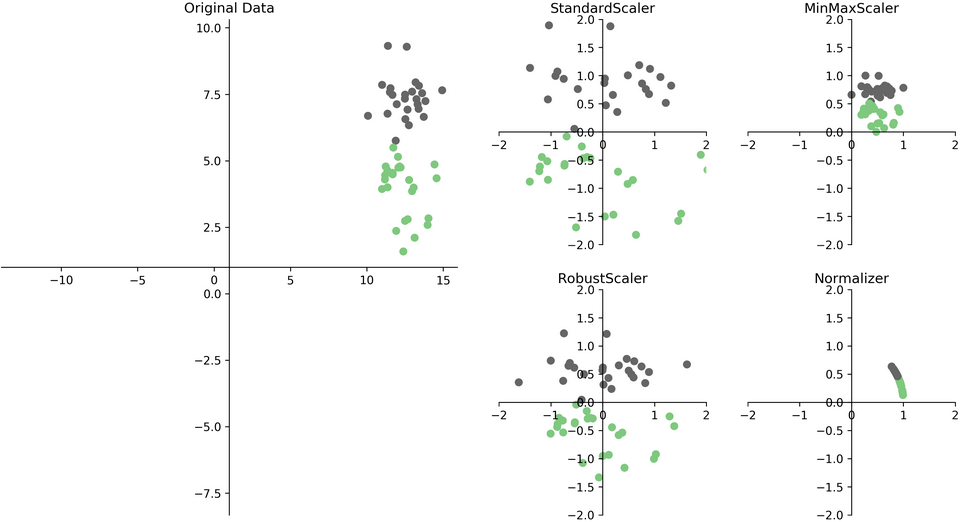 |
|---|
| Hình 1: Dữ liệu ban đầu (trái) và dữ liệu sau khi chuẩn hóa bằng 4 thuật toán trên (phải). 1 |
Ở đây, PCA sẽ sử dụng Stardard Scaling nên ta sẽ trình bày chi tiết về thuật toán đó. Thuật toán Standard Scaling sẽ đưa từng thuộc tính của dữ liệu về giá trị trung bình bằng 0 và phương sai bằng 1 (\(\mu = 0, \sigma^2 = 1\))
\[\text{Với mỗi giá trị } i,j: \\ x_j^{(i)} := \frac{x_j^{(i)} - \mu_j}{\sigma_j} \\ \text{Với: } \\ \mu_j = \frac{1}{n} \sum_{i=1}^n x_j^{(i)} \\ \sigma_j^2 = \frac{1}{n} \sum_{i=1}^n \left(x_j^{(i)} - \mu_j\right)^2\\\]Thuật toán PCA
Phần tiếp theo ta sẽ trình bày PCA về mặt ý tưởng sau đó triển khai thuật toán một cách toán học.
Ý tưởng
Giả sử ta có tập dữ liệu gồm các điểm dữ liệu thuộc \(\mathbb{R}^2\), và đây là tập dữ liệu sau khi được chuẩn hóa.
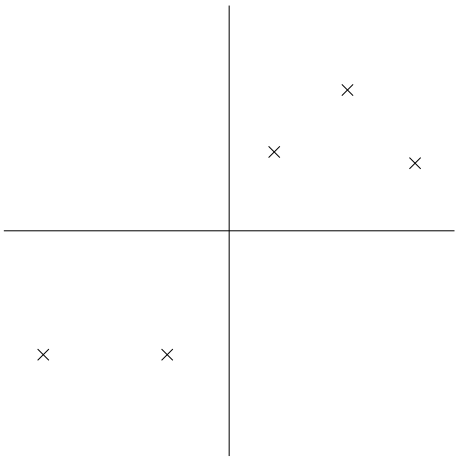 |
|---|
| Hình 2: Dữ liệu sau khi được chuẩn hóa. Trục tung và trục hoành là trục thể hiện thuộc tính của dữ liệu. 2 |
Một cách trực quan, khi nhìn vào tập dữ liệu, ta thấy được thông tin về mối quan hệ giữa hai thuộc tính được thể hiện qua phương sai của tập dữ liệu (hay hiệu phương sai của hai thuộc tính). Nói cách khác, nếu một điểm dữ liệu có thuộc tính 1 lớn thì thuộc tính 2 cũng sẽ lớn, và ngược lại (hiệu phương sai dương). Vì lẽ đó, nên khi ta mang những điểm dữ liệu trên vào không gian thấp chiều hơn (trong trường hợp này là \(\mathbb{R}\)) thì ta muốn ý nghĩa về phương sai trên vẫn được bảo toàn.
Cụ thể hơn, ta muốn tìm những vector đơn vị \(u\) sao cho, khi ta chiếu những điểm dữ liệu lên đường thẳng có \(u\) là vector chỉ hướng thì phương sai của những điểm dữ liệu mới được tối đa.
Để hiểu rõ hơn về cách chọn vector \(u\), ta sẽ xem qua hai trường hợp mà ở đó một trường hợp vector \(u\) được chọn tốt còn trường hợp còn lại thì không.
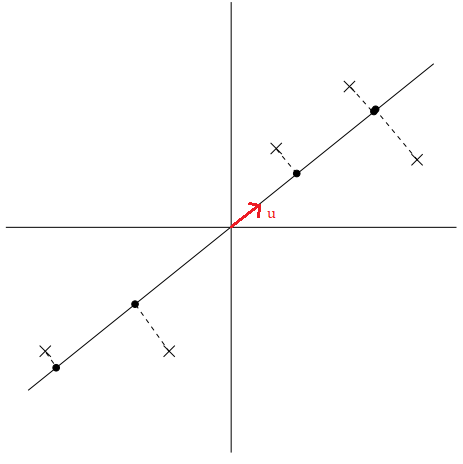 |
|---|
| Hình 3: Các điểm dữ liệu được chiếu lên đường thẳng có \(u\) là vector chỉ hướng tốt. 2 |
Ta thấy những điểm dữ liệu mới (chấm đen) được chiếu lên đường thẳng có \(u\) là vector chỉ hướng vẫn cách nhau khá xa, hay có phương sai lớn. Những điểm dữ liệu mới (chấm đen) thể hiện khá tốt những điểm dữ liệu ban đầu (dấu x). Ngược lại với cách chọn trên, ta có cách chọn vector \(u\) không được tốt.
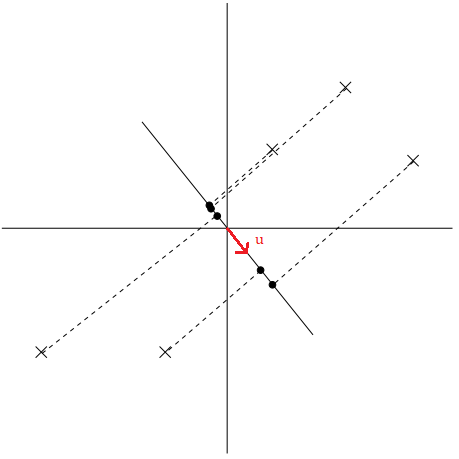 |
|---|
| Hình 4: Các điểm dữ liệu được chiếu lên đường thẳng có \(u\) là vector chỉ hướng không tốt. 2 |
Trong trường hợp này, những điểm dữ liệu mới (chấm đen) rất gần nhau, hay có phương sai nhỏ, đây không phải là cách thể hiện tốt cho những điểm dữ liệu ban đầu (dấu x).
Tóm lại, ý tưởng của PCA là tìm ra những vector \(u\) sao cho, khi ta chiếu những điểm dữ liệu ban đầu lên các đường thẳng có \(u\) là vector chỉ hướng thì những điểm dữ liệu mới sẽ có phướng sai lớn. Sau khi tìm được \(k\) vector \(u\) lần lượt là \(u_1, u_2,...,u_k\) thì ta sẽ chiếu điểm dữ liệu lên \(k\) đường thẳng có \(u_1, u_2,...,u_k\) lần lượt là vector chỉ hướng, sẽ có được điểm dữ liệu trong tọa độ mới thuộc \(\mathbb{R}^k\) (việc làm này sẽ được cụ thể hơn trong phần trình bày bằng toán học).
\[x^{(i)} \in \mathbb{R}^d \rightarrow x^{(i)'} \in \mathbb{R}^k\]Qua đó ta rút ra được những nhận xét:
- Phương sai của tập dữ liệu mới sẽ đúng bằng trung bình cộng của bình phương khoảng cách của những điểm dữ liệu mới đến gốc tọa độ bởi vì tập dữ liệu đã được chuẩn hóa cho giá trị trung bình là 0.
- Những vector \(u_1, u_2,...,u_k\) độc lập tuyến tính với nhau vì mục đích của PCA là “nén” các điểm dữ liệu vào một chiều không gian nhỏ hơn nên nếu có một vector \(u_j\) là tổ hợp tuyến tính của những vector \(u\) còn lại thì tọa độ được thể hiện bằng vector \(u_j\) xem như bị “thừa”.
- \(k < d\). Dễ hiểu vì ta đang muốn giảm chiều của dữ liệu.
Trình bày toán học
Để thuận tiện trong việc trình bày, ta gọi hành động chiếu điểm dữ liệu \(x\) lên đường thẳng nhận \(u\) làm vector chỉ hướng là chiếu điểm dữ liệu \(x\) lên vector \(u\).
Ma trận chiếu của vector
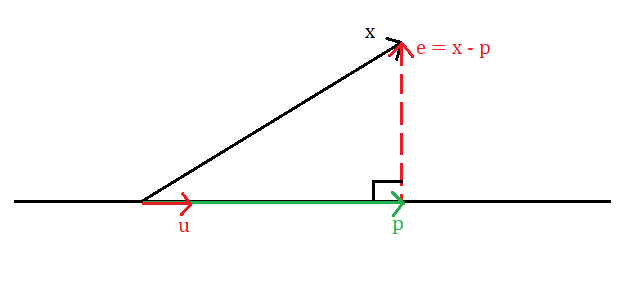
Trước tiên, ta sẽ nhắc lại cách tìm hình chiếu của vector \(x\) lên vector \(u\)
 |
|---|
| Hình 5: Quá trình chiều vector \(x\) lên vector \(u\). |
Trong hình vẽ, vector \(p\) (màu xanh) là vector có được sau khi thực hiện phép chiếu vector \(x\) lên vector \(u\). Bằng phép trừ vector ta thu được vector \(e = x - p\) vuông góc với vector \(p\). Ngoài ra, vector \(e\) còn được gọi là vector residual.
Ma trận chiếu của vector \(x\) lên vector \(u\) là ma trận \(P\) sao cho:
\[p = Px\]Một cách toán học, chiều của vector và ma trận phải là:
\[x,u,p,e \in \mathbb{R}^d \\ P \in \mathbb{R}^{d \times d}\]Ta sẽ bắt đầu tìm lại ma trận \(P\). Vì vector \(u\) và vector \(p\) cùng phương nên ta đặt \(p = ku\) với \(k \in \mathbb{R}\). Vì \(u \perp e\) nên:
\[\begin{aligned} u^T e &= 0 \\ u^T (x- p) &= 0 \\ u^T (x- ku) &= 0 \\ ku^Tu &= u^Tx \\ k &= \frac{u^T x}{u^T u} \end{aligned}\]Từ đó, ta có:
\[\begin{aligned} p &= ku \\ &= uk \\ &= u \frac{u^T x}{u^T u} \\ &= \frac{u u^T}{u^T u} x \end{aligned}\]Vậy:
\[P = \frac{u u^T}{u^T u}\]Mô hình toán học
Ta có tập dữ liệu đã được chuẩn hóa \(\{x^{(1)}, x^{(2)},.., x^{(n)}\}\) với \(x^{(i)} \in \mathbb{R}^d\). Ta cần tìm những vector đơn vị \(u \in \mathbb{R}^d, u^Tu = 1\) sao cho, khi chiếu những điểm dữ liệu lên vector \(u\) thì trung bình cộng của bình phương khoảng cách của những điểm dữ liệu mới đến gốc tọa độ lớn nhất.
Áp dụng tính chất đã trình bày, ta sẽ tìm vector hình chiếu của vector \(x\) lên \(u\).
\[p = Px = \frac{u u^T}{u^T u} x = uu^Tx \quad (\because u^Tu = 1)\]Từ đó, ta tìm được độ lớn của vector hình chiếu hay khoảng cách của những điểm dữ liệu mới đến gốc tọa độ.
\[\text{\textbardbl}p\text{\textbardbl} =\text{\textbardbl}uu^T x\text{\textbardbl} = \text{\textbardbl}u^Tx\text{\textbardbl} = \text{\textbardbl}x^Tu\text{\textbardbl} = x^T u \quad(\because u^Tu=1)\]Vậy mục tiêu trở thành, tìm vector đơn vị \(u\) sao cho đại lượng sau được tối đa:
\[\begin{aligned} \frac{1}{n} \sum_{i=1}^n \left(x^{(i)^T} u\right)^2 &= \frac{1}{n} \sum_{i=1}^n u^T x^{(i)} x^{(i)^T} u \\ &= u^T \left( \frac{1}{n} \sum_{i=1}^n x^{(i)} x^{(i)^T} \right)u \\ &= u^T \Sigma u \end{aligned}\]Với \(\Sigma = \frac{1}{n} \sum_{i=1}^n x^{(i)} x^{(i)^T}\)
Vì tập dữ liệu đã được chuẩn hóa nên có giá trị trung bình là 0, do đó ma trận \(\Sigma\) là ma trận hiệu phương sai của tập dữ liệu.
Qua phép biến đổi trên, bài toán trở thành bài toán tối ưu hóa.
\[\text{Tối đa} \quad f(u) = u^T \Sigma u \\ \text{Với} \quad u^Tu = 1\]Ta giải quyết bài toán bằng cách xây dựng hàm Lagrangian:
\[\mathcal{L}(u;\lambda) = u^T \Sigma u + \lambda(u^Tu - 1)\]Vì ma trận \(\Sigma\) là một ma trận đối xứng nên lấy đạo hàm riêng của hàm Lagrangian theo biến \(u\) và giải nghiệm ta được:
\[\begin{aligned} \frac{\partial \mathcal{L}}{\partial u} &= 0 \\ 2 \Sigma u - 2 \lambda u &= 0 \\ \Sigma u &= \lambda u \end{aligned}\]Ta thấy, \(u\) là vector riêng và \(\lambda\) là giá trị riêng tương ứng của ma trận \(\Sigma\). Từ đó, hàm mục tiêu cần tối đa \(f(u)\) trở thành:
\[\begin{aligned} f(u) &= u^T \Sigma u \\ &= u^T \lambda u &\quad (\because \Sigma u = \lambda u) \\ &= \lambda u^T u \\ &= \lambda &\quad (\because u^T u = 1) \end{aligned}\]Vậy, để tối đa hàm mục tiêu \(f(u)\) thì vector \(u\) phải là vector riêng ứng với giá trị riêng lớn nhất của ma trận \(\Sigma\).
Tóm tắt lại, ta vừa tìm được không gian con một chiều để xấp xỉ tập dữ liệu ban đầu bằng cách chiếu từng điểm dữ liệu lên vector \(u\). Tổng quát hơn, nếu ta muốn chiếu tập dữ liệu ban đầu lên một không gian con \(k\) chiều (\(k < d\)) thì ta sẽ chọn \(u_1, u_2,...,u_k\) là \(k\) vector riêng ứng với \(k\) giá trị riêng lớn nhất của ma trận \(\Sigma\). Các vector \(u_1, u_2,...,u_k\) còn được gọi là \(k\) principal components đầu tiên của dữ liệu
Ngoài ra, \(k\) vector \(u\) tạo thành một hệ cơ sở trực chuẩn mới cho dữ liệu. Ta thể hiện điểm dữ liệu \(x^{(i)}\) trong hệ cơ sở mới bằng cách tìm vector \(y^{(i)}\) tương ứng.
\[y^{(i)} = \begin{bmatrix} \rule[.5ex]{1.5em}{0.4pt} & u_1^T & \rule[.5ex]{1.5em}{0.4pt} \\ \rule[.5ex]{1.5em}{0.4pt} & u_2^T & \rule[.5ex]{1.5em}{0.4pt} \\ & \vdots & \\ \rule[.5ex]{1.5em}{0.4pt} & u_k^T & \rule[.5ex]{1.5em}{0.4pt} \end{bmatrix} x^{(i)} \in \mathbb{R}^k\]Cách chọn số chiều của không gian con (k)
Giả sử sau khi thực hiện phân rã trị riêng trên ma trận \(\Sigma\) ta thu được \(d\) giá trị riêng \(\lambda_1, \lambda_2,...,\lambda_d\) được sắp xếp theo thứ tự giảm dần. Khi này, ta có thể chọn \(k\) bằng cách tìm giá trị \(k\) nhỏ nhất sao cho:
\[\frac{\sum_{i=1}^k \lambda_i}{\sum_{i=1}^d \lambda_i} \geq r\]Với \(r\) là siêu tham số thỏa mãn \(0 \leq r \leq 1\).
Ta có thể hiểu, siêu tham số \(r\) thể hiện số phần trăm thông tin của dữ liệu ta muốn bảo toàn sau khi thực hiện PCA.
Ngoài ra, ta có thể thực hiện PCA trước, sau đó lựa chọn giá trị siêu tham số \(r\) sau.
Ma trận hóa
Để việc trình bày súc tích và thuật toán được triển khai nhanh trên các thư viện tính toán của python, ta sẽ đưa dữ liệu vào các ma trận.
Bắt đầu với tập dữ liệu \(\{x^{(1)}, x^{(2)},.., x^{(n)}\}\) với \(x^{(i)} \in \mathbb{R}^d\), ta sẽ đưa những điểm dữ liệu \(x^{(i)}\) vào các cột của ma trận \(X\)
\[X = \begin{bmatrix} \vert & \vert & & \vert \\ x^{(1)} & x^{(2)} & \dots & x^{(n)} \\ \vert & \vert & & \vert \end{bmatrix} \in \mathbb{R}^{d \times n}\]Bằng cách nhân ma trận, ta thu được kết quả
\[\Sigma = \frac{1}{n} \sum_{i=1}^n x^{(i)} x^{(i)^T} = \frac{1}{n} XX^T \in \mathbb{R}^{d \times d}\]Sau khi thực hiện phân rã trị riêng ma trân \(\Sigma\), ta đưa \(k\) vector riêng \(u_1, u_2,...,u_k\) vào các hàng của ma trận \(U\)
\[U = \begin{bmatrix} \rule[.5ex]{1.5em}{0.4pt} & u_1^T & \rule[.5ex]{1.5em}{0.4pt} \\ \rule[.5ex]{1.5em}{0.4pt} & u_2^T & \rule[.5ex]{1.5em}{0.4pt} \\ & \vdots & \\ \rule[.5ex]{1.5em}{0.4pt} & u_k^T & \rule[.5ex]{1.5em}{0.4pt} \end{bmatrix} \in \mathbb{R}^{k \times d}\]Vậy tọa độ mới của các điểm dữ liệu sẽ là các cột của ma trận \(Y\)
\[UX = \begin{bmatrix} \rule[.5ex]{1.5em}{0.4pt} & u_1^T & \rule[.5ex]{1.5em}{0.4pt} \\ \rule[.5ex]{1.5em}{0.4pt} & u_2^T & \rule[.5ex]{1.5em}{0.4pt} \\ & \vdots & \\ \rule[.5ex]{1.5em}{0.4pt} & u_k^T & \rule[.5ex]{1.5em}{0.4pt} \end{bmatrix} \begin{bmatrix} \vert & \vert & & \vert \\ x^{(1)} & x^{(2)} & \dots & x^{(n)} \\ \vert & \vert & & \vert \end{bmatrix} = \begin{bmatrix} \vert & \vert & & \vert \\ y^{(1)} & y^{(2)} & \dots & y^{(n)} \\ \vert & \vert & & \vert \end{bmatrix} = Y \in \mathbb{R}^{k \times n}\]Thuật toán PCA
Khi này ta có thể phát biểu thuật toán PCA một cách hoàn thiện.
Input: Ma trận dữ liệu \(X\), siêu tham số \(r\).
- Chuẩn hóa \(X\).
- Tính \(\Sigma = \frac{1}{n} XX^T\).
- Phân rã trị riêng \(\Sigma\) thu được \(d\) vector riêng \(u_1, u_2,...,u_d\) ứng với các giá trị riêng \(\lambda_1, \lambda_2,..., \lambda_d\) được sắp xếp theo thứ tự giảm dần.
- Chọn giá trị \(k\) nhỏ nhất sao cho \(\frac{\sum^k \lambda_i}{\sum^d \lambda_i} \geq r\).
- Đưa \(k\) vector riêng đầu tiên vào các hàng của ma trận \(U\).
- Tính \(Y = UX\).
Output: Ma trận dữ liệu mới \(Y\).
Xây dựng PCA theo cách khác
Nhắc lại phần trước, ta chọn vector đơn vị \(u\) sao cho trung bình cộng của bình phương độ lớn vector hình chiếu \(p\) của vector \(x\) lên \(u\) lớn nhất, hay:
\[u = \arg \max_u \frac{1}{n} \sum_{i=1}^n \left(x^{(i)^T} u\right)^2\]Ngoài ra, ta có một bài toán tương đương là chọn vector đơn vị \(u\) sao cho trung bình cộng của bình phương độ lớn vector residual \(e = x - p\) nhỏ nhất, hay:
\[\begin{aligned} u &= \arg \min_u \frac{1}{n} \sum_{i=1}^n \text{\textbardbl}x^{(i)} - p^{(i)}\text{\textbardbl}^2 \\ &= \arg \min_u \frac{1}{n} \sum_{i=1}^n \text{\textbardbl}x^{(i)} - u u^T x^{(i)}\text{\textbardbl}^2 \\ &= \arg \min_u \frac{1}{n} \sum_{i=1}^n \left(x^{(i)} - u u^T x^{(i)}\right)^T \left(x^{(i)} - u u^T x^{(i)}\right) \\ &= \arg \min_u \frac{1}{n} \sum_{i=1}^n \left( x^{(i)^T} x^{(i)} - 2 \left( u^T x^{(i)}\right)^2 + u^T u \left(u^T x^{(i)}\right)^2 \right) \\ &= \arg \min_u \frac{1}{n} \sum_{i=1}^n \left( x^{(i)^T} x^{(i)} - 2 \left( u^T x^{(i)}\right)^2 + \left(u^T x^{(i)}\right)^2 \right) \quad (\because u^Tu = 1)\\ &= \arg \min_u \frac{1}{n} \sum_{i=1}^n - \left(u^T x^{(i)} \right)^2 \\ &= \arg \max_u \frac{1}{n} \sum_{i=1}^n \left(x^{(i)^T} u \right)^2 \end{aligned}\]Vậy ta đã chứng minh được hai bài toán trên tương đương với nhau.
Ứng dụng của PCA
PCA có nhiều ứng dụng, ta sẽ tìm hiểu một vài ứng dụng đó.
Đầu tiên, PCA dùng để nén dữ liệu qua việc thể hiện điểm dữ liệu \(x^{(i)}\) bằng điểm dữ liệu \(y^{(i)}\) trong không gian mới thấp chiều hơn. Nếu ta giảm chiều dữ liệu về \(k=2\) hoặc \(k=3\), ta có thể vẽ các điểm dữ liệu mới \(y^{(i)}\) trong không gian \(\mathbb{R}^2\) hoặc \(\mathbb{R}^3\). Từ đó, qua hình vẽ ta có thể đưa ra nhận xét về cấu trúc của dữ liệu, như những điểm dữ liệu tương đồng thường ở gần nhau thành cụm.
Tiếp đến, PCA dùng để tiền xử lý dữ liệu. Ta có thể giảm chiều cho các điểm dữ liệu \(x^{(i)}\) trước khi cho vào thuật toán học có giám sát. Ngoài tác dụng để giảm thời gian tính toán, việc giảm chiều dữ liệu còn giảm độ phức tạp của các hàm giả thiết tránh việc overfitting thường xảy ra trong các thuật toán học có giám sát.
Cuối cùng, PCA còn được xem như thuật toán giảm nhiễu cho dữ liệu. Ta có thể thấy rõ ứng dụng trong việc nhận diện vật thể trong ảnh, ví dụ ta có một bức ảnh chân dung 128x128 pixels trên thang độ xám được thể hiện bằng một vector \(x \in \mathbb{R}^{128 \times 128}\), khi này \(x\) là vector trong không gian 16384 chiều. Ta chụp khuôn mặt của nhiều người, sau mỗi lần chụp, khuôn mặt có thể khác nhau và điều kiện môi trường có thể bị thay đổi. Khi này, những điểm dữ liệu tạo thành một tập dữ liệu \(X\). Ta thực hiện PCA trên tập dữ liệu đó và thu được \(d\) principal components \(u_1, u_2,..., u_d \in \mathbb{R}^{16384}\). Ta mong đợi những principal components \(u_1, u_2,..., u_d\) là những đặc điểm nền tảng của khuôn mặt người khi loại bỏ những yếu tố gây nhiễu như: sự chêch lệnh ánh sáng, sự thay đổi trong môi trường chụp ảnh,… (Ngoài ra, các vector \(u_1, u_2,...,u_d\) còn được gọi là các “eigenfaces”). Tiếp đến, ta đưa những principal components \(u_1, u_2,..., u_d\) vào các hệ thống học nhận diện vật thể để cho kết quả tối ưu. Đây là một ứng dụng khá cũ của PCA trong xử lí hình ảnh, ngày nay các hệ thống học sâu được sử dụng trong nhận diện vật thể chỉ cần dữ liệu được chuẩn hóa thì hệ thống sẽ cho ra hiệu quả rất cao chứ không cần phải sử dụng các thuật toán xử lí rời rạc như PCA. (Các bạn có thể tìm từ khóa “eigenface” để xem ảnh, vì hình hơi đáng sợ nên mình không đưa vào :D)
Triển khai PCA trong python
Trong phần này, ta sẽ tạo tập dữ liệu giả bao gồm 3 thuộc tính độc lập và 2 thuộc tính được tạo nên từ 2 trong 3 thuộc tính độc lập và thêm vào số gây nhiễu. Trên tập dữ liệu vừa tạo được ta lần lượt triển khai thuật toán PCA của thư viện scikit-learn và thuật toán PCA tự xây dựng. Do cách tập dữ liệu được tạo ra như trên, nên ta mong đợi thuật toán trả về một tập dữ liệu mới trong không gian \(\mathbb{R}^3\) và giữ lại được tương đối nhiều thông tin.
Thư viện cần thiết
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
Xây dựng dữ liệu
Ta lấy 1000 điểm dữ liệu ngẫu nhiên từ một phân phối chuẩn nhiều biến \(\mathcal{N}(0, I_{3 \times 3})\).
Thuộc tính thứ 4 bằng thuộc tính thứ 1 cộng thêm một số gây nhiễu được lấy từ phân phối chuẩn \(\mathcal{N}(0, 1)\). Hay một cách toán học: \(x_4 = x_1 + \epsilon\) với \(\epsilon \sim \mathcal{N}(0, 1)\).
Thuộc tính thứ 5 bằng thuộc tính thứ 2 cộng thêm một số gây nhiễu được lấy từ phân phối chuẩn \(\mathcal{N}(0, 1)\). Hay một cách toán học: \(x_5 = x_2 + \epsilon\) với \(\epsilon \sim \mathcal{N}(0, 1)\).
data = pd.DataFrame(np.random.standard_normal((1000, 3)), columns=['x_1', 'x_2', 'x_3'])
data['x_12'] = data['x_1'] + np.random.standard_normal(1000)
data['x_22'] = data['x_2'] + np.random.standard_normal(1000)
10 điểm dữ liệu đầu tiên của tập dữ liệu:
| x_1 | x_2 | x_3 | x_12 | x_22 | |
|---|---|---|---|---|---|
| 0 | -0.104956 | -1.602666 | -0.746589 | 0.000711 | -0.843164 |
| 1 | 0.985981 | 1.769158 | 0.529060 | 1.406641 | 0.678612 |
| 2 | -0.451795 | 0.927669 | -1.088793 | -0.927991 | 1.527098 |
| 3 | -0.583225 | 2.169625 | 0.635159 | 1.865672 | 3.452182 |
| 4 | 0.695683 | 0.924896 | 0.136483 | 1.149004 | -1.324765 |
| 5 | 0.319727 | -2.103935 | -0.618945 | -1.307749 | -2.915871 |
| 6 | -0.898247 | 0.281593 | 0.447593 | -1.974785 | -0.526757 |
| 7 | 1.839951 | 0.428175 | -0.479016 | 1.938443 | 1.839200 |
| 8 | -0.253375 | 1.493829 | -0.460393 | -1.132856 | 0.914950 |
| 9 | 0.750355 | 0.553638 | 0.520859 | 0.995447 | -1.680824 |
PCA của thư viện scikit-learn
Vì PCA của scikit-learn không trực tiếp hỗ trợ chuẩn hóa dữ liệu nên đầu tiên ta sẽ thực hiện chuẩn hóa dữ liệu bằng StandardScaler.
scaled_data = StandardScaler().fit_transform(data)
10 điểm dữ liệu đầu tiên của tập dữ liệu sau khi đã chuẩn hóa:
| x_1 | x_2 | x_3 | x_12 | x_22 | |
|---|---|---|---|---|---|
| 0 | -0.136994 | -1.611005 | -0.718743 | -0.026567 | -0.577244 |
| 1 | 0.915577 | 1.720680 | 0.555608 | 0.943183 | 0.493353 |
| 2 | -0.471635 | 0.889208 | -1.060599 | -0.667145 | 1.090279 |
| 3 | -0.598444 | 2.116379 | 0.661598 | 1.259804 | 2.444611 |
| 4 | 0.635488 | 0.886468 | 0.163430 | 0.765477 | -0.916060 |
| 5 | 0.272754 | -2.106307 | -0.591229 | -0.929086 | -2.035432 |
| 6 | -0.902387 | 0.250823 | 0.474223 | -1.389179 | -0.354646 |
| 7 | 1.739514 | 0.395660 | -0.451443 | 1.309998 | 1.309849 |
| 8 | -0.280194 | 1.448628 | -0.432838 | -0.808453 | 0.659622 |
| 9 | 0.688237 | 0.519629 | 0.547414 | 0.659559 | -1.166554 |
Triển khai thuật toán PCA:
pca = PCA().fit(scaled_data)
Vẽ đồ thị sự phụ thuộc của “Phần trăm thông tin được bảo toàn (%)” với “Số chiều của không gian con”
plt.plot(np.arange(1,6), 100 * np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('Chiều của không gian con')
plt.ylabel('Phần trăm thông tin được bảo toàn (%)')
plt.xticks(np.arange(1,6))
plt.grid()
plt.show()
 |
|---|
| Hình 6: Đồ thị sự phụ thuộc của “Phần trăm thông tin được bảo toàn (%)” với “Số chiều của không gian con” |
Như được dự đoán ở phần mở đầu, số chiều của không gian con là 3 sẽ bảo toàn gần 90% thông tin.
Ta sẽ triển khai lại thuật toán PCA với số chiều không gian con là 3:
pca = PCA(n_components=3).fit(scaled_data)
transformed_data = pd.DataFrame(pca.transform(scaled_data), columns=['x_1', 'x_2', 'x_3'])
10 điểm dữ liệu đầu tiên của tập dữ liệu sau khi được đưa vào không gian \(\mathbb{R}^3\):
| x_1 | x_2 | x_3 | |
|---|---|---|---|
| 0 | 0.893049 | -1.228696 | 0.777021 |
| 1 | -0.083939 | 2.071402 | -0.455980 |
| 2 | -1.683841 | 0.379668 | 0.861742 |
| 3 | -1.851660 | 2.688211 | -0.777881 |
| 4 | 0.741922 | 0.695305 | -0.017572 |
| 5 | 1.647348 | -2.463856 | 0.689215 |
| 6 | -1.017713 | -1.159880 | -0.676756 |
| 7 | 0.618802 | 2.330974 | 0.659760 |
| 8 | -1.628825 | 0.503613 | 0.246420 |
| 9 | 1.072540 | 0.374732 | -0.378429 |
PCA tự xây dựng
Ta sẽ xây dựng PCA theo hướng đối tượng tương tự như thư viện scikit-learn. Cụ thể hơn, ta sẽ tạo PCA là một class, khi sử dụng ta sẽ tạo một instance của class đó. Trong class sẽ có những methods phục vụ cho thuật toán.
Kiến trúc của class
-
Tên class: simple_PCA.
- Attribute: principal_components (Ma trận chứa tất cả eigenvectors của \(\Sigma\)), eigenvalues (Những giá trị eigenvalues tương ứng), scaled_data (Dữ liệu đã được chuẩn hóa), scores (Phần trăm thông tin được bảo toàn)
- Method: init(), fit(X, isStandardized=False), transform_k(n_components), transform_r(r), plot_scores().
Method init()
Đặt principal_components, eigenvalues, scaled_data và scores là None.
def __init__(self):
self.principal_components = None
self.eigenvalues = None
self.scaled_data = None
self.scores = None
Method fit(X, isStandardized=False)
Nếu isStandardized là False thì sẽ thực hiện chuẩn hóa dữ liệu, ngược lại thì không (Mặc định là False). Tính ma trận \(\Sigma\), thực hiện phân rã trị riêng và gán các vector riêng và giá trị riêng lần lượt cho principal_components và eigenvalues, cập nhật scaled_data và scores.
def fit(self, X, isStandardized=False):
'''
Input:
X: ndarray, shape (n, d).
isStandardized: boolean.
Output: None
'''
n, d = X.shape
# Chuẩn hóa dữ liệu
if (not isStandardized):
mean = X.mean(axis=0)
std = X.std(axis=0)
self.scaled_data = (X - mean) / std
else:
self.scaled_data = X
# Tính ma trận Sigma
Sigma = 1/n * self.scaled_data.T @ self.scaled_data
# Thực hiện phân rã trị riêng
eigenvalues, eigenvector = np.linalg.eig(Sigma)
# Cập nhật principal_components và eigenvalues
sorted_index = np.argsort(eigenvalues)[::-1]
self.eigenvalues = eigenvalues[sorted_index]
self.principal_components = eigenvector[sorted_index]
#Cập nhật scores
self.scores = 100 * np.cumsum(self.eigenvalues / self.eigenvalues.sum())
Method transform_k(n_components)
Trả về tập dữ liệu mới trong không gian con n_components chiều.
def transform_k(self, n_components):
'''
Input:
n_components: int.
Output:
Y: ndarray, shape (n, n_components).
'''
return self.scaled_data @ self.principal_components[:n_components].T
Method transform_r(r)
Trả về tập dữ liệu với ít nhất r phần trăm thông tin được bảo toàn.
def transform_r(self, r):
'''
Input:
r: float, 0 <= r <= 100.
Output:
Y: ndarray, shape (n, n_components).
'''
n_components = np.searchsorted(self.scores, r) + 1
return self.scaled_data @ self.principal_components[:n_components].T
Method plot_scores()
Vẽ đồ thị sự phụ thuộc của “Phần trăm thông tin được bảo toàn (%)” với “Số chiều của không gian con”.
def plot_scores(self):
n, d = self.scaled_data.shape
plt.plot(np.arange(1, d+1), self.eigenvalues)
plt.xlabel('Chiều của không gian con')
plt.ylabel('Phần trăm thông tin được bảo toàn (%)')
plt.xticks(np.arange(1, d+1))
plt.grid()
plt.show()
Kết quả
Khởi tạo một instance simple_PCA và fit dữ liệu:
pca = simple_PCA()
pca.fit(data)
Vẽ đồ thị sự phụ thuộc của “Phần trăm thông tin được bảo toàn (%)” với “Số chiều của không gian con”.
pca.plot_scores()
 |
|---|
| Hình 7: Đồ thị sự phụ thuộc của “Phần trăm thông tin được bảo toàn (%)” với “Số chiều của không gian con” |
Biến đổi dữ liệu bằng transform_k(3) và xem 5 điểm dữ liệu đầu tiên.
pca.transform_k(3)
| x_1 | x_2 | x_3 | |
|---|---|---|---|
| 0 | -0.179461 | -0.983026 | 0.654038 |
| 1 | -0.323677 | -1.029329 | 0.006958 |
| 2 | 0.548274 | 0.847151 | -0.344913 |
| 3 | -1.208117 | -0.349382 | 1.392836 |
| 4 | -0.683511 | 0.742557 | 0.081008 |
Biến đổi dữ liệu bằng transform_r(80) và xem 5 điểm dữ liệu đầu tiên.
pca.transform_r(80)
| x_1 | x_2 | x_3 | |
|---|---|---|---|
| 0 | -0.179461 | -0.983026 | 0.654038 |
| 1 | -0.323677 | -1.029329 | 0.006958 |
| 2 | 0.548274 | 0.847151 | -0.344913 |
| 3 | -1.208117 | -0.349382 | 1.392836 |
| 4 | -0.683511 | 0.742557 | 0.081008 |
Code Link
https://github.com/iamnmt/blog-code/blob/main/principal-component-analysis.ipynb
Kết luận
PCA là một thuật toán cổ điển trong giảm chiều dữ liệu. Cách xây dựng thuật toán dễ hiểu và áp dụng khá đơn giản nên thuật toán vẫn được sử dụng tương đối nhiều. Ngày nay, PCA thường được dùng chủ yếu trong việc tiền xử lý dữ liệu cho ra một tập dữ liệu gọn, súc tích để chuyển vào các thuật toán học có giám sát tiếp theo.
Thuật ngữ đã sử dụng
| Tiếng Việt | Tiếng Anh | Tiếng Việt | Tiếng Anh |
|---|---|---|---|
| Chuẩn hóa | Standardize | Học sâu | Deep learning |
| Cụm | Cluster | Không gian con | Subspace |
| Đạo hàm riêng | Partial Derivative | Ma trận chiếu | Projection matrix |
| Điểm dữ liệu | Datapoint | Phân phối chuẩn nhiều biến | Multivariate gaussian distribution |
| Giá trị riêng | Eigenvalue | Phân rã trị riêng | Eigendecomposition |
| Giá trị trung bình | Mean | Phương sai | Variance |
| Giảm chiều dữ liệu | Dimensionality reduction | Siêu tham số | Hyperparameter |
| Giảm nhiễu | Noise reduction | Tập dữ liệu | Dataset |
| Hệ cơ sở trực chuẩn | Orthogonal basis | Thang độ xám | Greyscale |
| Hiệu phương sai | Covariance | Thuộc tính | Feature |
| Học có giám sát | Supervised learning | Vector riêng | Eigenvector |
| Học không giám sát | Unsupervised Learning |